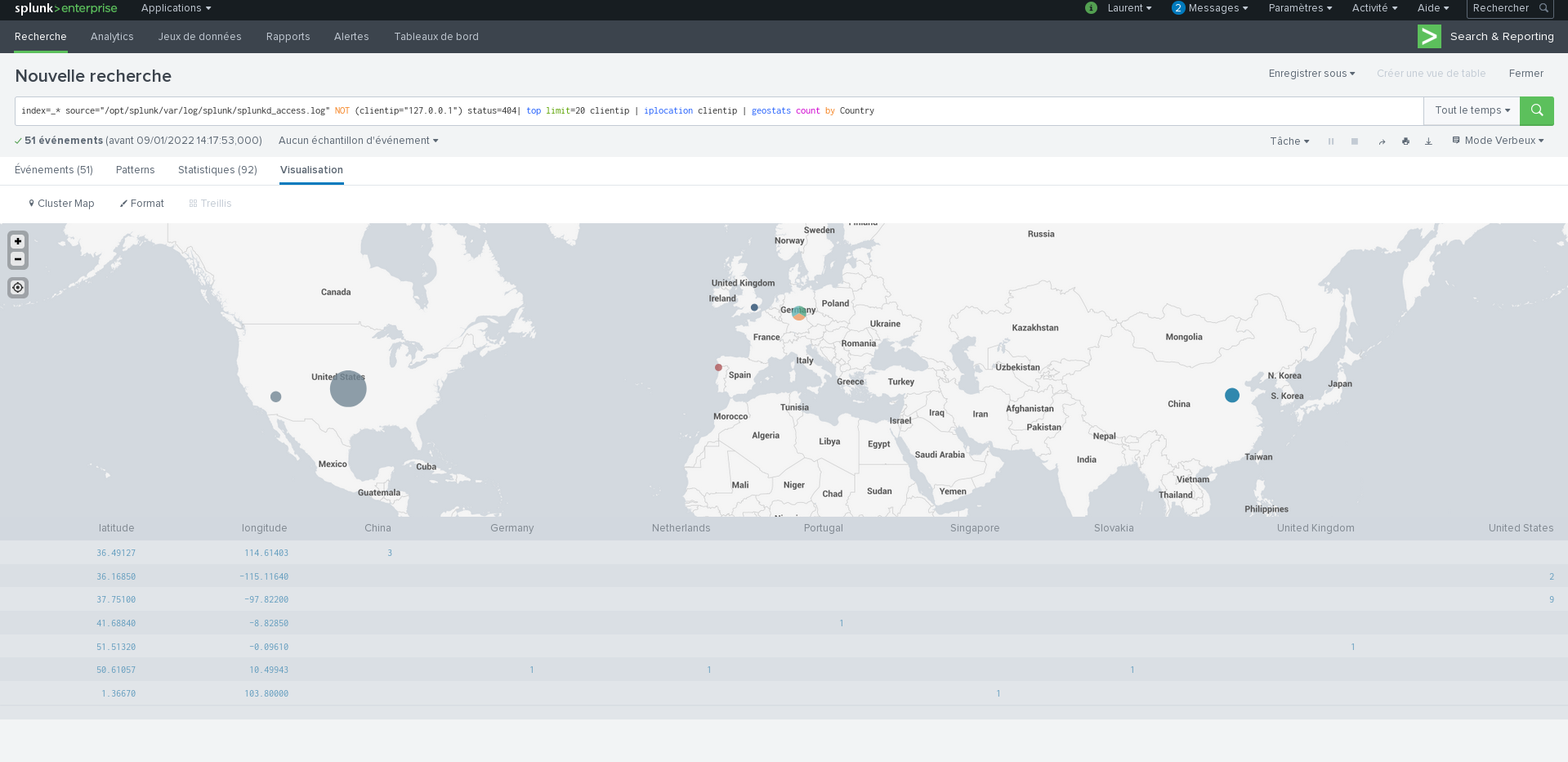
Posted on 13 octobre 2021.
Je pose ça là !
L’inspection SSL/TLS, comment ca marche ?
J’ai un flux chiffré entre mon serveur et mon navigateur et je veux voir son contenu à l’ancienne (après je détaillerai comment on fait de l’inspection avec Kaspesrsky security endpoint chez mon employeur).
On va commencer par se mettre dan un cas favorable. Ce qui n’est pas le cas quand vous avez déployé HTTPS sur/etc/letsencrypt/options-ssl-apache.conf votre site web comme un bourrin avec CERTBOT (mais merci quand même Let’s Encrypt).
Conf de base
Ca ne me plait pas, donc je vais désactiver Diffie-Hellman. Laissez moi faire du SSL 2.1 avec rien que du RSA, please 🙂
This task provides the procedure to disable Diffie-Hellman on Apache Servers by editing the SSLCipherSuite config option string in the ssl.conf or httpd.conf files.
Procedure
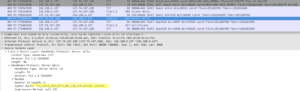
In Apache’s conf directory, locate file: ssl.conf or httpd.conf
Look for the SSLCipherSuite keyword string value:

Apache Cipher Suite
To disable Diffie-Hellman, please insert « !EDH:!DHE:!DH:!ECDH » after the « ALL: » in the cipher spec.
This is an example and you will need to make sure you include it to all the variants of Diffie-Hellman to disable it on your web server.
For additional info: https://httpd.apache.org/docs/current/mod/mod_ssl.html#sslciphersuite
Repeat this edit in every SSL config section, if you are not using one global section.
Save the file.
Restart the web server for the changes to take effect.
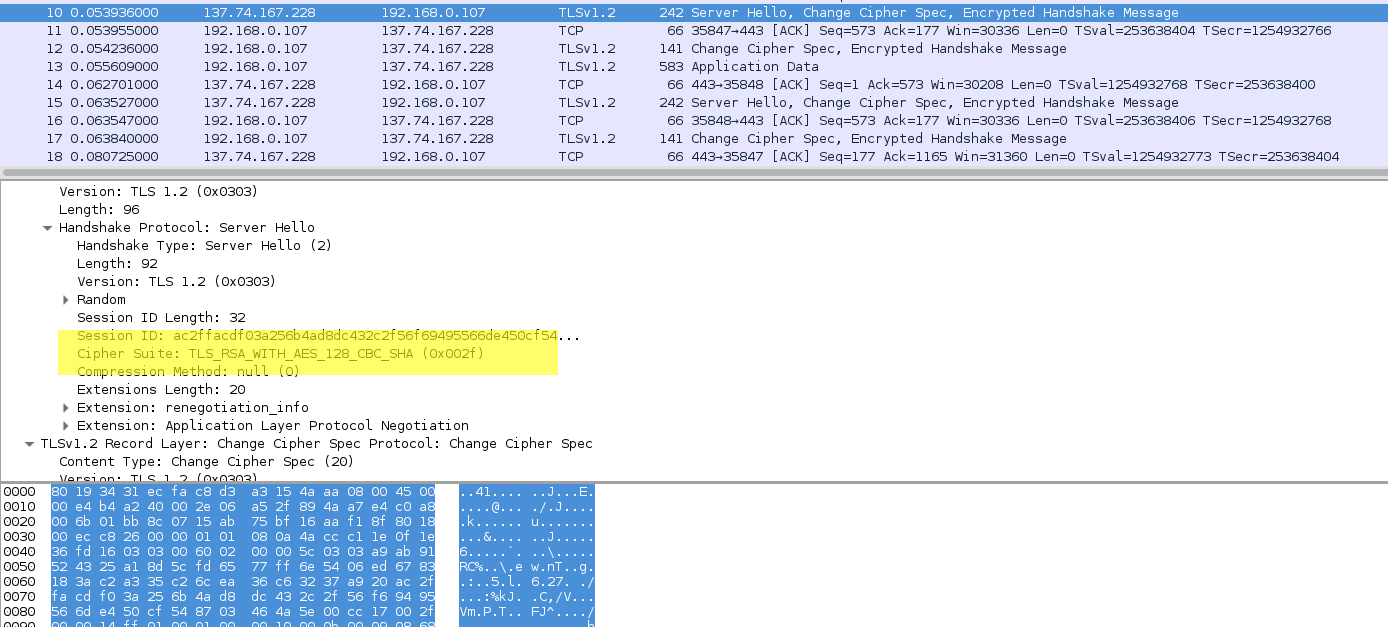
Après quelques essais infructueux, il faut bien se rendre à l’évidence que cela ne fonctionne pas 🙂
On se dit donc que la conf de base a du être surchargée par CERTBOT. Bingo !
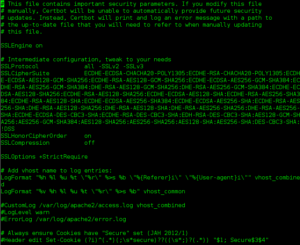
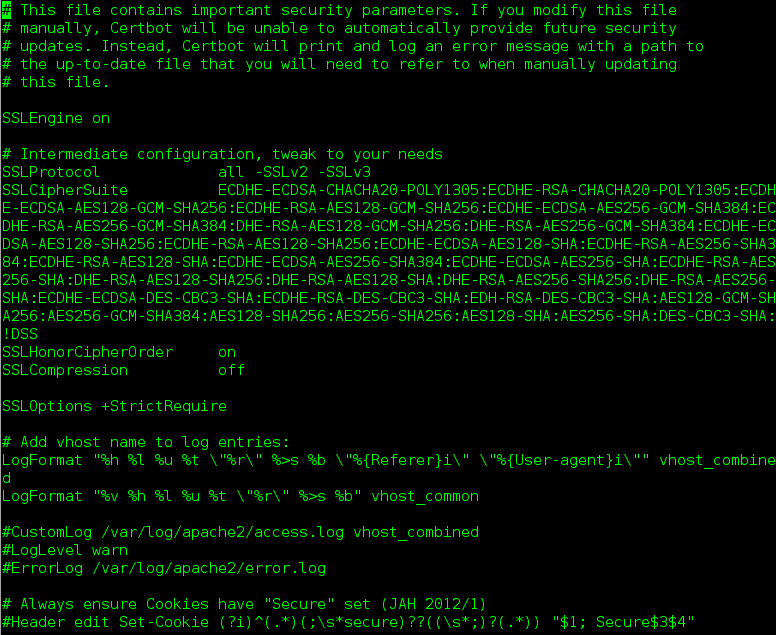
Real Cipher Suite Conf
SSLCipherSuite ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES256-SHA:ECDHE-ECDSA-DES-CBC3-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS
Un petit nettoyage s’impose donc dans /etc/letsencrypt/options-ssl-apache.conf
On va simplifier à :
SSLCipherSuite AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS
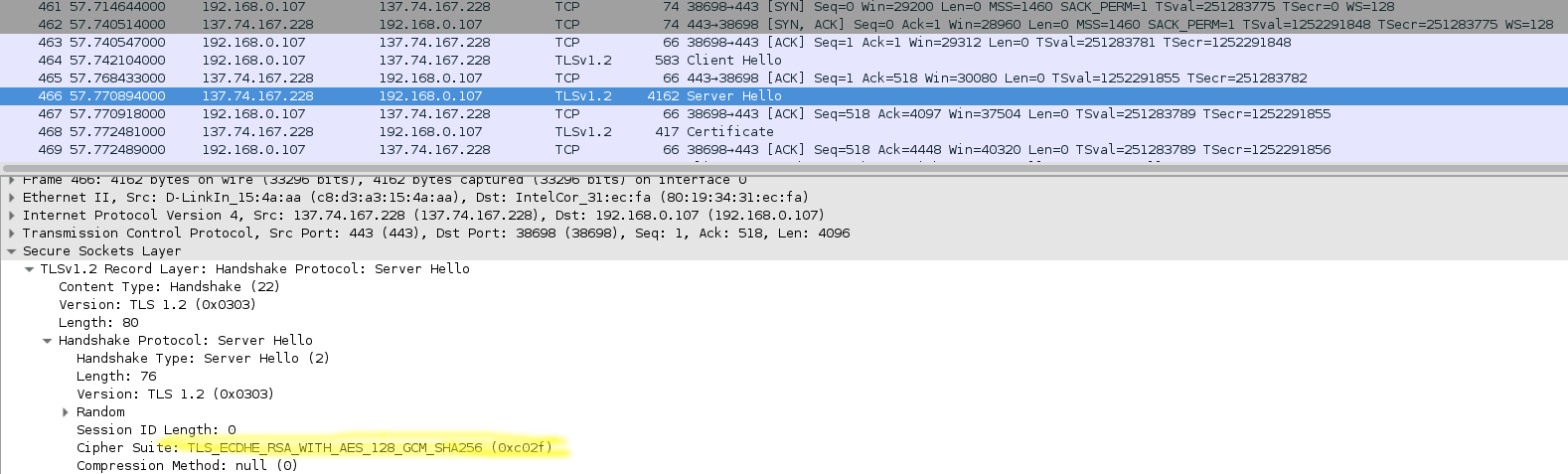
Du coup, Wireshark confirme le changement de cipher:
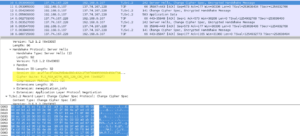
I Love RSA
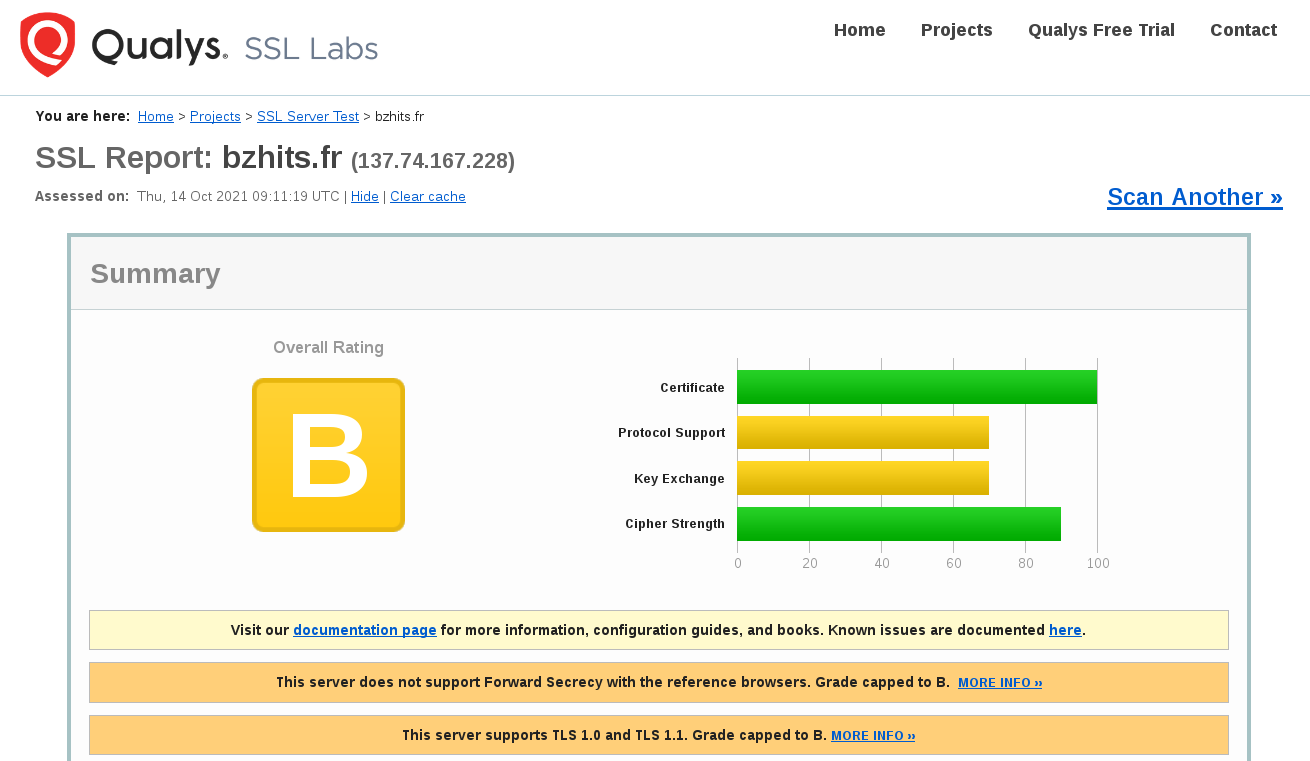
Qualys SSL Labs nous confirme cette dégradation du niveau de sécurité :
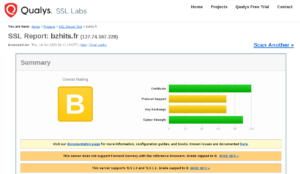
SSL Labs
« This server does not support Forward Secrecy with the reference browsers. Grade capped to B » … et oui, d’où l’intérêt de Diffie-Helmann !
En revanche pour « This server supports TLS 1.0 and TLS 1.1. Grade capped to B », on peut certainement faire quelquechose. En particulier, ajouter TLSv1 et TLSv1.1 de la liste des protocoles supportés dans /etc/letsencrypt/options-ssl-apache.conf
C’est là que les choses sérieuses commencent.
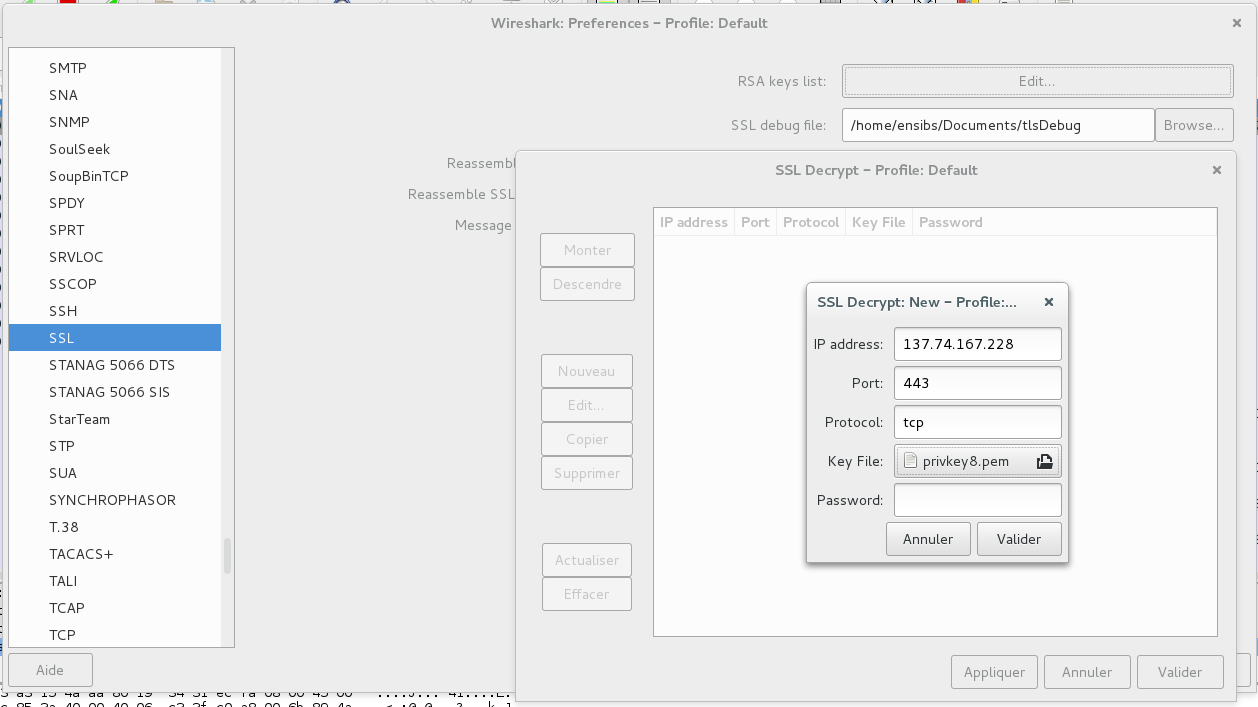
Afin de déchiffrer le flux https, nous allons récupérer la clef privée de notre serveur Apache et la fournir à wireshark. En principe, c’est par ce genre de manipulations hasardeuses que nos précieuses clefs privés finissent dans la nature. En l’occurrence, pas vraiment de sensibilité pour cette plateforme de démo.
Le chemin vers la clef est renseigné dans /etc/letsencrypt/options-ssl-apache.conf
Je décrirai bientôt ailleurs comment cette clef intervient dans une phase amont du chiffrement de flux. Elle sert juste à « calculer » la véritable clef de chiffrement symétrique du flx entre chacun des navigateurs qu se se connectent notre serveur Apache.
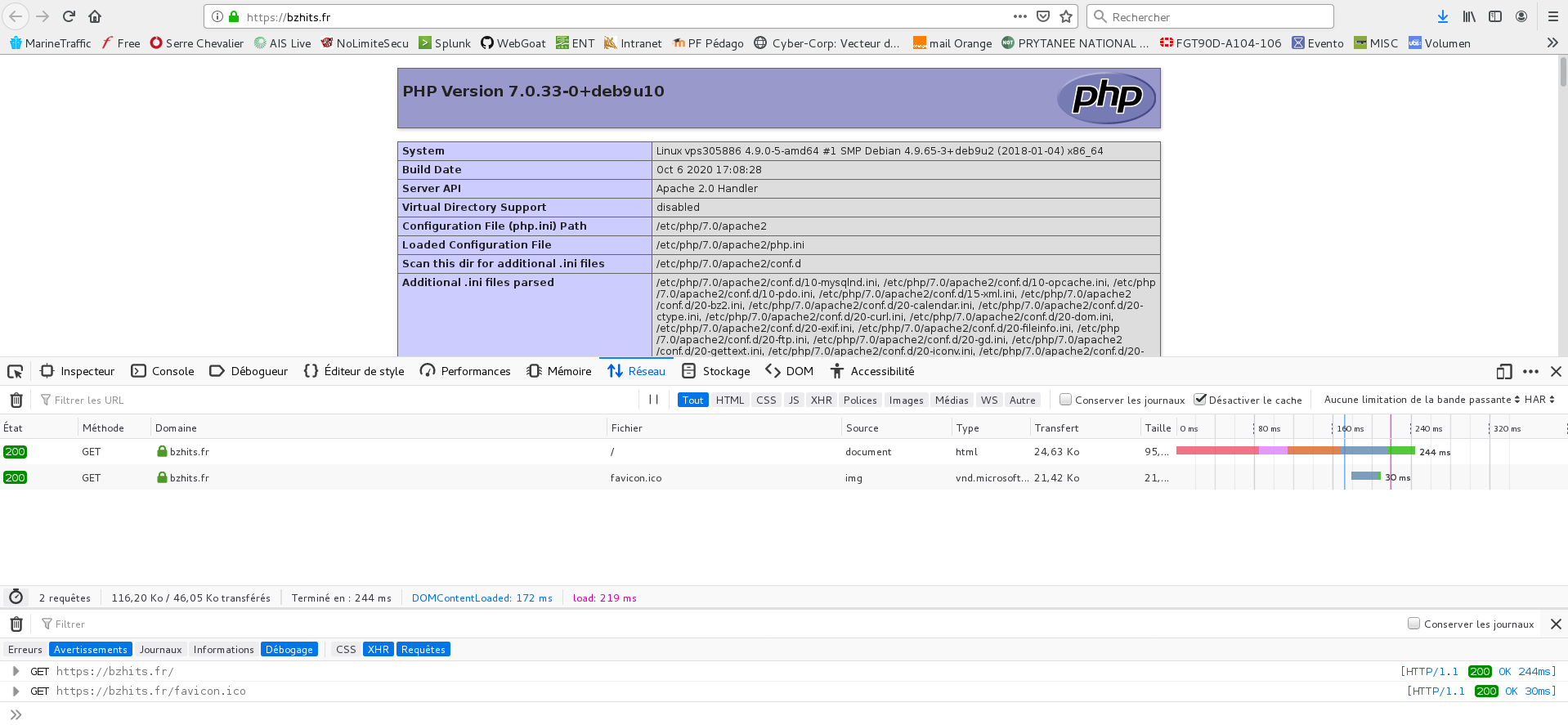
Le serveur web est exposé directement sur internet et semble fonctionner correctement :
bzhits.fr
Pour faciliter la tâche aux attaquants, il expose via sa page index.php le contenu d’un phpinfo(). C’est un pauvre VPS chez OVH qui donne toute satisfaction. Il sert par ailleurs récupérer des logs du bruit de l’internet…
Cadenas vert pour monsieur Noël, tout semble ok en termes de sécu.
phpinfo()
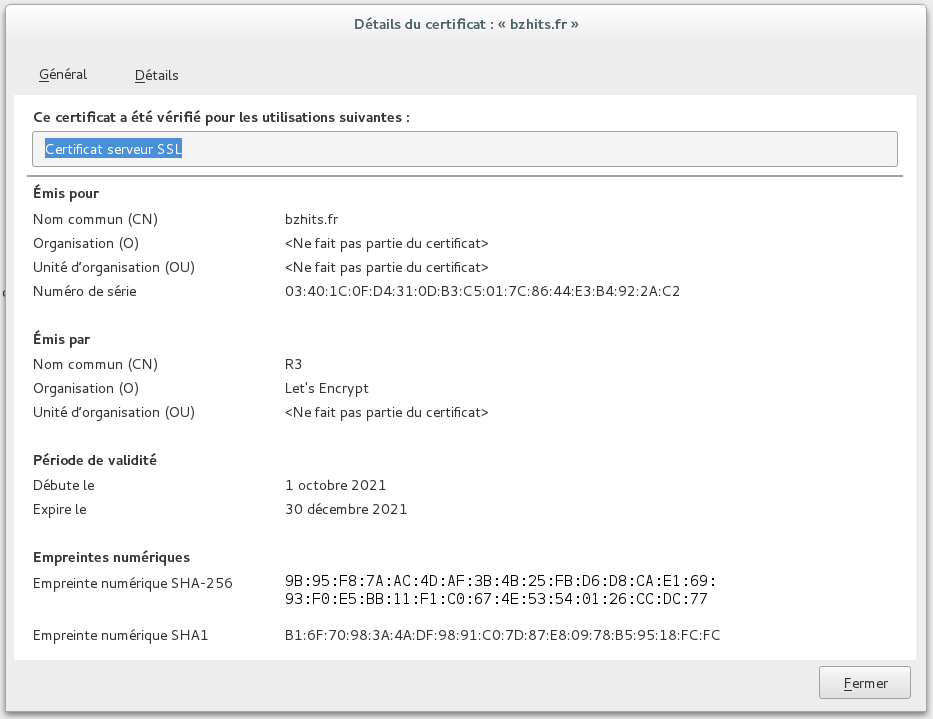
Le certificat SSL ( que je n’aime pas cette appellation !!!) présenté à l’air de correspondre au serveur considéré, nous sommes tranquilles jusqu’au 31 décembre 2021.
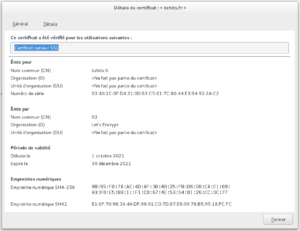
Certificat X509
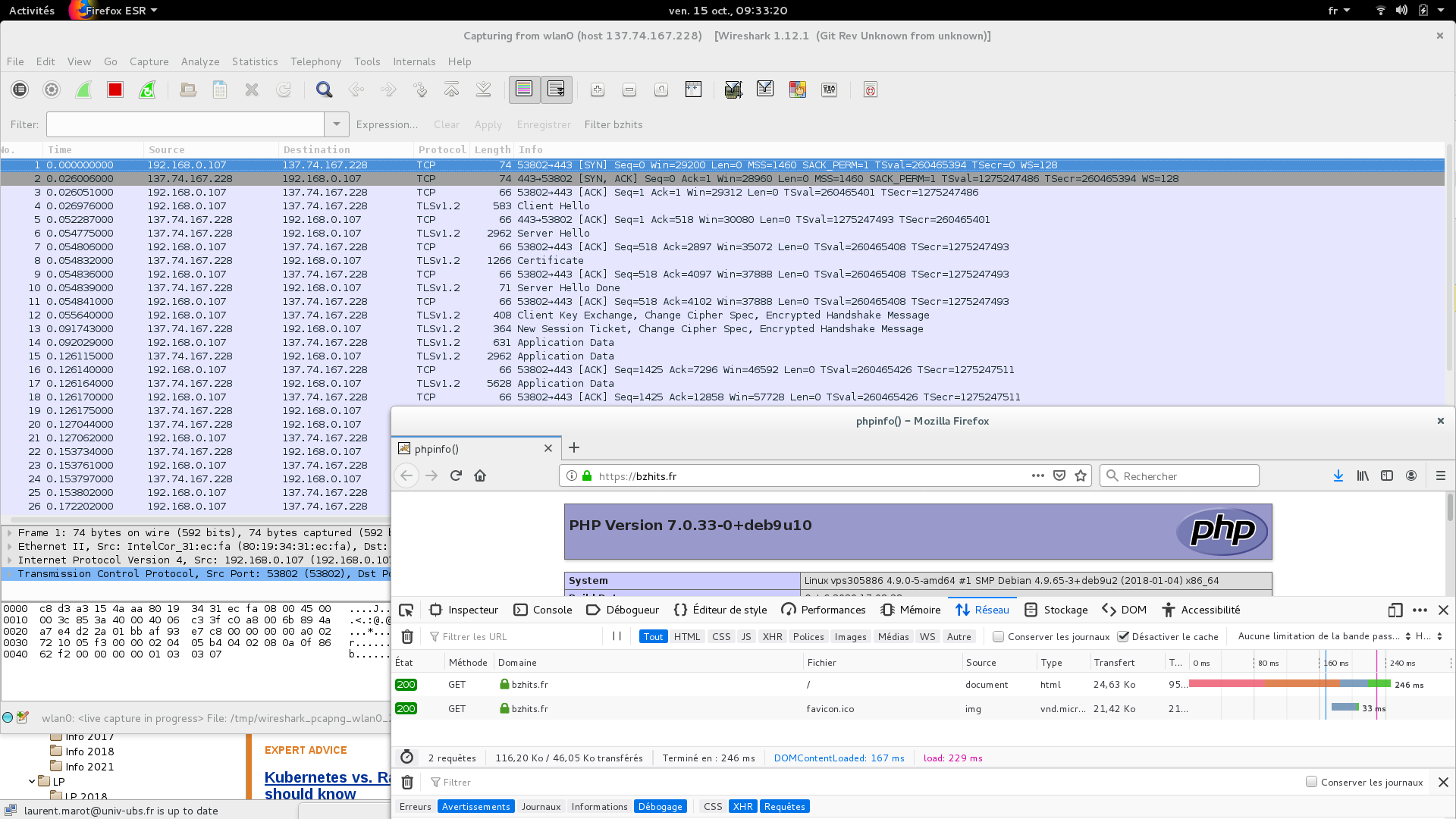
Une première analyse brute du flux confirme un certain nombre d’évidences :
– l’appli répond normalement
– le flux est bien chiffré et débute par le traditionnel « TCP handshake »
– on fait du TLS1.2 over HTTP 1.1
– setup : wireshark (1.12.1) sur Debian intercepte mon interface wan avec filtre de capture sur l’IP du serveur (vsible dans l’entête de la fenêtre)
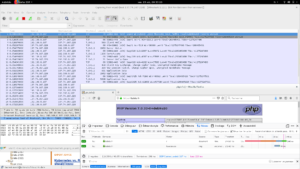
Capture réseau
Afin qu’il puisse déchiffrer le flux, on va fournir la clef privée du serveur à Wireshark.
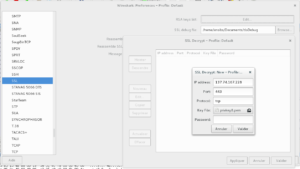
Plz, give me your Private Key
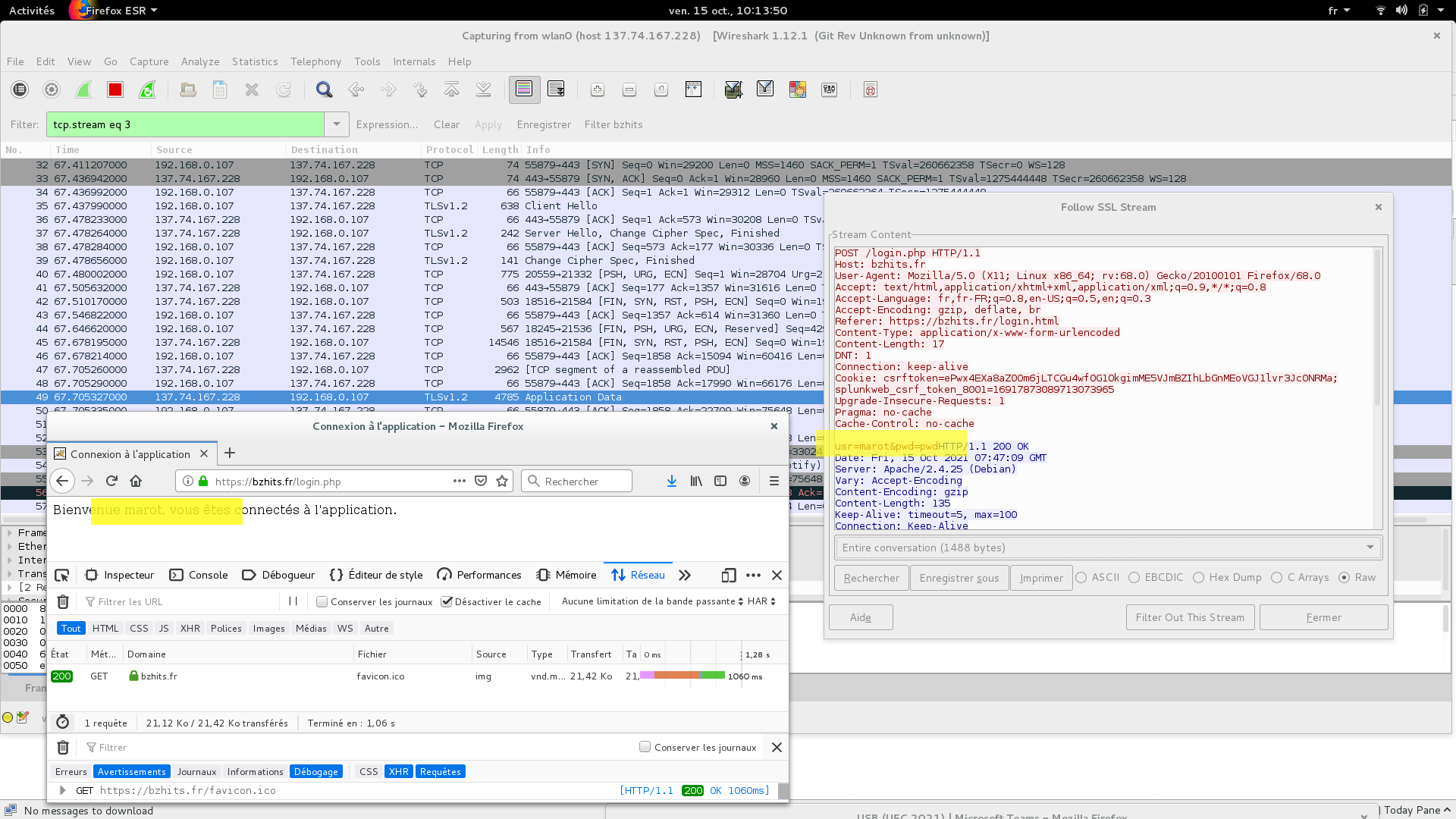
Pour le coup, j’ai crée un formulaire minimaliste (login.html) qui demande un identifiant et un mot de passe à un utilisateur pour le transmettre via requête POST à une page de traitement (login.php).
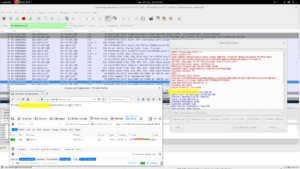
pwd leak
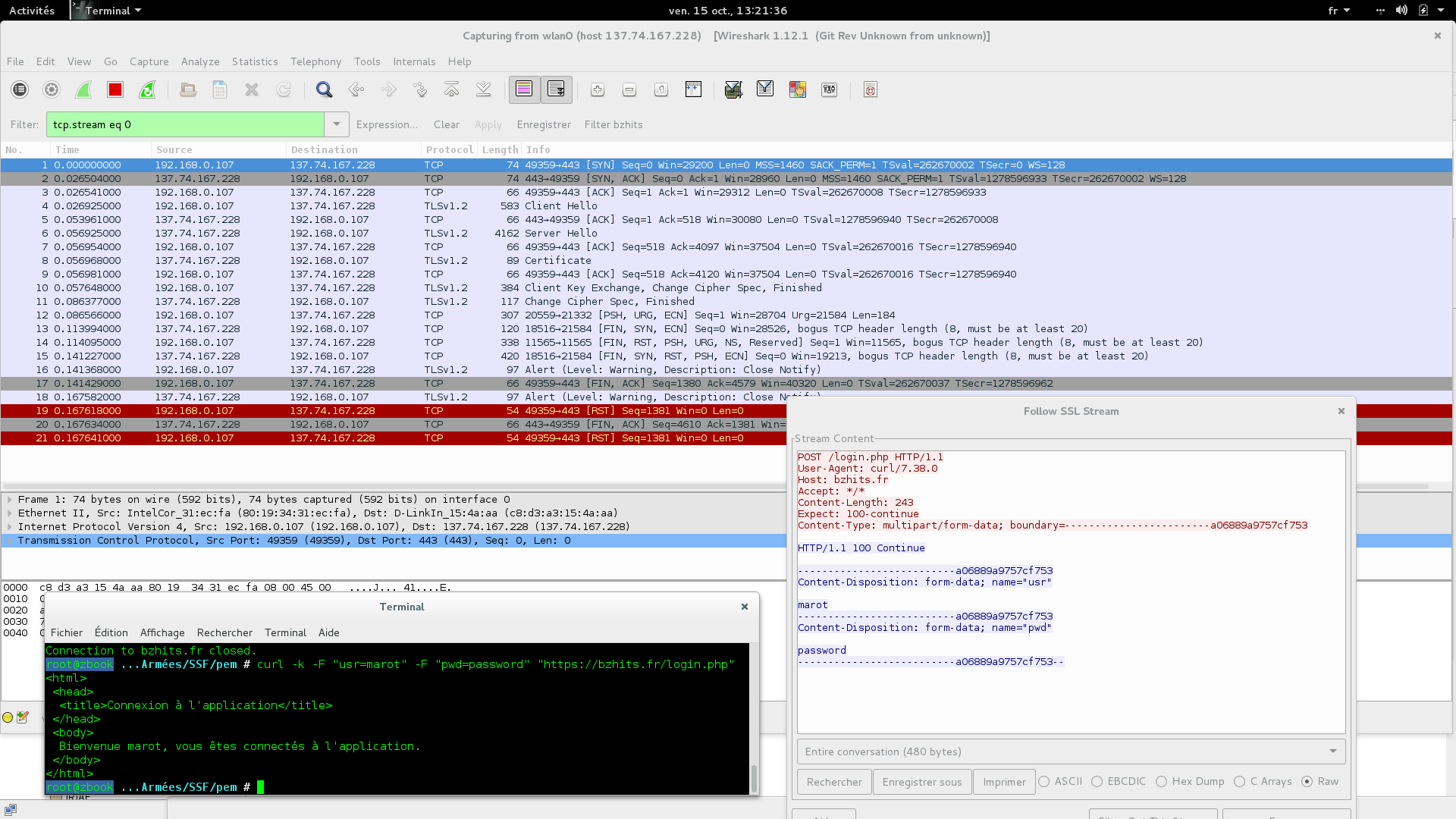
Grâce à l’interception TLS, on voit très bien passer les informations de connexion (marot / pwd).
Pour un truc plus propre dans Wireshark, préférez passer vos requêtes en ligne de commande via cUrl : curl -k -F « usr=marot » -F « pwd=password » « https://bzhits.fr/login.php »
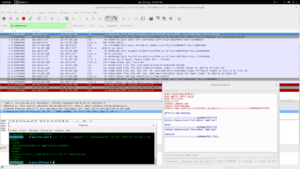
CQFD step 1
Bon, maintenant que cela fonctionne avec touts les précautions précédentes, voyons comment s’adapter au cas où l’administrateur de votre site ait eu la bonne idée d’utiliser Diffie-Helmann. Car vous avez bien compris que si dans 3 mois ou dans 10 quelqu’un trouve votre clef privée et ressort des captures réseau, RIP la confidentialité.
Tout cela était déjà fort bien expliqué par Benjamin aka @vincib lors des confs mémorables « Il était une fois l’internet »
____________________________________________________________________________________
Pour pouvoir écrire ces quelques lignes, j’ai du réapprendre à surligner du texte dans une image avec The Gimp (p’tain je préfère snap/capture sous Windows), modifier les fichiers de traductions .po/.mo wordpress avec poEdit, retrouver l’accès ssh à ce vieux VPS chez OVH, appliquer les mises à jours Worpress sans faire de sauvegarde, réviser ma conf Apache / mod_ssl pour pour les nuls…. Bref, ça m’a pris des plombes…
L’objectif initial de cet article était de proposer une explication sur un vieux chall root-me SSL – HTTP exchange qui était lui même une re-sucée d’un challenge qualif DEF CON préhistorique… et aussi de me servir de base pratique pratique pour une formation que je donnerai sous peu.
Pour aller plus loin, maintenant que vous avez compris le principe, je vous laisse trouver l’appliance sécu qui va bien pour faire la même chose de manière industrielle … dans le respect de la loi … et en accod avec votre perception de l’éthique.
J’espère que cela vous donnera aussi l’envie de lire les Recommandations de sécurité relatives à TLS de l’ANSSI téléchargeables à cette adresse : https://www.ssi.gouv.fr/uploads/2017/07/anssi-guide-recommandations_de_securite_relatives_a_tls-v1.2.pdf