
Splunk
Quelques conseils ici pour réaliser nos tests..Installation et configuration de Splunk
C’est fou ce que ce petit outil me dit de vous.
J’ai caché 2 ou 3 trucs rigolos sur ce site, saurez-vous les découvrir ?
Posted on 25 novembre 2020.
Splunk
Quelques conseils ici pour réaliser nos tests..Installation et configuration de Splunk
C’est fou ce que ce petit outil me dit de vous.
J’ai caché 2 ou 3 trucs rigolos sur ce site, saurez-vous les découvrir ?
Posted in Boulot0 commentaire
Posted on 04 octobre 2020.
Posted in BoulotSaisissez votre mot de passe pour accéder aux commentaires.
Posted on 17 avril 2020.
Posted in Boulot, CryptoSaisissez votre mot de passe pour accéder aux commentaires.
Posted on 10 avril 2020.
Very first thing : Read That F*** Manual !
$JAVA_HOME/bin/keytool -genkey -alias tomcat -keyalg RSA
and specify a password value of « whatYouWantButNotChangeIt ».
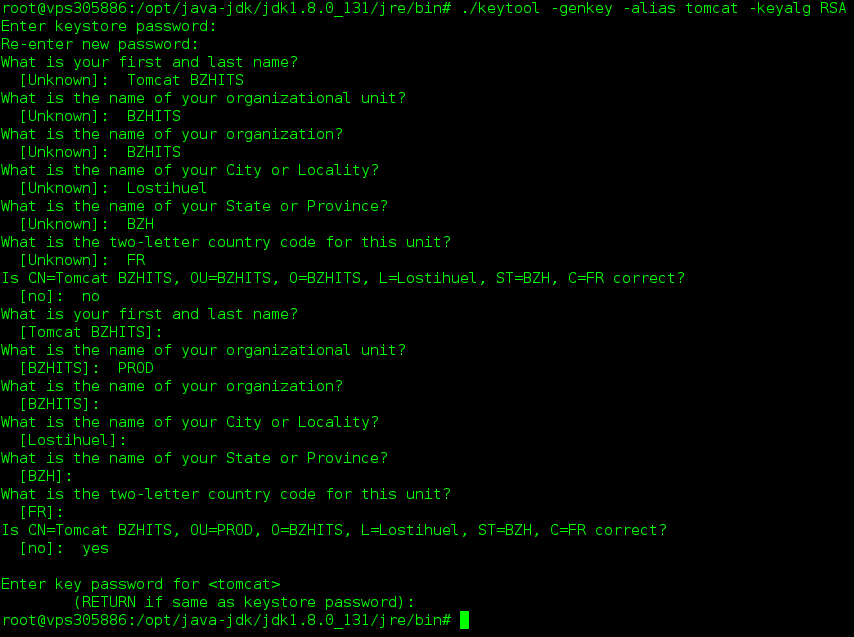
keystore
Edit your server.xml file, beware that commented examples provided could be very far from what youy need :
<!-- Define an SSL Coyote HTTP/1.1 Connector on port 8443 -->
<Connector
protocol="org.apache.coyote.http11.Http11NioProtocol"
port="8443" maxThreads="200"
scheme="https" secure="true" SSLEnabled="true"
keystoreFile="${user.home}/.keystore" keystorePass="changeit"
clientAuth="false" sslProtocol="TLS"/>
<Connector port="8443" protocol="org.apache.coyote.http11.Http11NioProtocol"
maxThreads="150" SSLEnabled="true" scheme="https" secure="true"
keystoreFile="/root/.keystore"
keystorePass="***********"
clientAuth="false" sslProtocol="TLS">
Posted in Boulot0 commentaire
Posted on 01 avril 2020.
Intégralement et honteusement pompé sur https://www.fil.univ-lille1.fr/~wegrzyno/portail/PAC/Doc/TP-Certificats/tp-certif002.html
On peut générer une paire de clés RSA avec la commande genrsa de openSSL.
$ openssl genrsa -out <fichier> <taille>
où fichier est un nom de fichier de sauvegarde de la clé, et taille et la taille souhaitée (exprimée en bits) du modulus de la clé.
Par exemple, pour générer une paire de clés de 1024 bits, stockée dans le fichier maCle.pem, on tape la commande
$ openssl genrsa -out maCle.pem 1024
Le fichier obtenu est un fichier au format PEM (Privacy Enhanced Mail, format en base 64), dont voici un exemple :
$ cat maCle.pem
-----BEGIN RSA PRIVATE KEY----- MIICXAIBAAKBgQCveVjLltevTC5kSAiTYjHMVuAR80DHMLWCp3BOVZ49eXwraXxO 7AfKWpA5g0wFZgZNERIfFYaCnvaQDQA+9BRIfsSSr3oSw0My5SD6eg15v0VmJmvP d8LgBypJHbr6f5MXWqntvzp0Qvg6ddeNpUIrqkkh4uDfHFDWqyrkQUCvKwIDAQAB AoGANchUrfnq28DWy0fE0R+cscvC292Z8jN8vrIBWxEk8iSlKU0om6v+a0g8wlP6 3gC6V66uxjY7xxdf7SD+/UykVl4PGFymhLtywSdGlgec3tLgBtV3ytJFilAVDBij LzQwUegCO4zt1JWYc6vvaVdNyQSaGIIeYGsNDWEYlOtDSlkCQQDVRn9JS15G8p+H
4Z0PbU9ZQg2L1u9/SD/kELVe3Kx1fdHulxH0v8V2AgPdXA29Nhi+TxUtC+V8CMc2 KXmAvFsHAkEA0qBDmjHMDPwcGaqbQ2lymYQIGlZ5TLQFA98Dey2uE+CB6pmS/e/Z ilu1IaasuE3vBzXfB/JU7DUkV++JQ7TtvQJBAL2s5dUch2sXqlOhjhpDP/eE7CE6 9WLAsbm2Nmd4YJRZYtQLXPfLeeSapC9BCCMHsnfGQ3H9i4mFEQ6VUi7w1Q8CQAQa pVaS09QI8Y86eM4GdvowzWud9b0d4N8jcFDtIfA3NrDYjzmte8KraMsgEUuCET9F
uHPSL/9uRagE/dq44s0CQCMQU4PMqkMtwzCFsV8ZqLmkDPn1binIAwRLYFcsQRDt gTi6rycz3Pk1hCVzBfyMd8zwqpwKmR5FoOXuJEv+mVg=
-----END RSA PRIVATE KEY-----
La commande rsa permet de visualiser le contenu d’un fichier au format PEM contenant une paire de clés RSA.
$ openssl rsa -in <fichier> -text -noout
L’option -text demande l’affichage décodé de la paire de clés. L’option -noout supprime la sortie normalement produite par la commande rsa.
Par exemple
$ openssl rsa -in maCle.pem -text -noout
Private-Key: (1024 bit)
modulus:
00:af:79:58:cb:96:d7:af:4c:2e:64:48:08:93:62: 31:cc:56:e0:11:f3:40:c7:30:b5:82:a7:70:4e:55: 9e:3d:79:7c:2b:69:7c:4e:ec:07:ca:5a:90:39:83: 4c:05:66:06:4d:11:12:1f:15:86:82:9e:f6:90:0d: 00:3e:f4:14:48:7e:c4:92:af:7a:12:c3:43:32:e5: 20:fa:7a:0d:79:bf:45:66:26:6b:cf:77:c2:e0:07: 2a:49:1d:ba:fa:7f:93:17:5a:a9:ed:bf:3a:74:42: f8:3a:75:d7:8d:a5:42:2b:aa:49:21:e2:e0:df:1c:
50:d6:ab:2a:e4:41:40:af:2b
publicExponent: 65537 (0x10001)
privateExponent:
35:c8:54:ad:f9:ea:db:c0:d6:cb:47:c4:d1:1f:9c: b1:cb:c2:db:dd:99:f2:33:7c:be:b2:01:5b:11:24: f2:24:a5:29:4d:28:9b:ab:fe:6b:48:3c:c2:53:fa: de:00:ba:57:ae:ae:c6:36:3b:c7:17:5f:ed:20:fe: fd:4c:a4:56:5e:0f:18:5c:a6:84:bb:72:c1:27:46: 96:07:9c:de:d2:e0:06:d5:77:ca:d2:45:8a:50:15: 0c:18:a3:2f:34:30:51:e8:02:3b:8c:ed:d4:95:98: 73:ab:ef:69:57:4d:c9:04:9a:18:82:1e:60:6b:0d:
0d:61:18:94:eb:43:4a:59
prime1:
00:d5:46:7f:49:4b:5e:46:f2:9f:87:e1:9d:0f:6d: 4f:59:42:0d:8b:d6:ef:7f:48:3f:e4:10:b5:5e:dc: ac:75:7d:d1:ee:97:11:f4:bf:c5:76:02:03:dd:5c: 0d:bd:36:18:be:4f:15:2d:0b:e5:7c:08:c7:36:29:
79:80:bc:5b:07
prime2:
00:d2:a0:43:9a:31:cc:0c:fc:1c:19:aa:9b:43:69: 72:99:84:08:1a:56:79:4c:b4:05:03:df:03:7b:2d: ae:13:e0:81:ea:99:92:fd:ef:d9:8a:5b:b5:21:a6: ac:b8:4d:ef:07:35:df:07:f2:54:ec:35:24:57:ef:
89:43:b4:ed:bd
exponent1:
00:bd:ac:e5:d5:1c:87:6b:17:aa:53:a1:8e:1a:43: 3f:f7:84:ec:21:3a:f5:62:c0:b1:b9:b6:36:67:78: 60:94:59:62:d4:0b:5c:f7:cb:79:e4:9a:a4:2f:41: 08:23:07:b2:77:c6:43:71:fd:8b:89:85:11:0e:95:
52:2e:f0:d5:0f
exponent2:
04:1a:a5:56:92:d3:d4:08:f1:8f:3a:78:ce:06:76: fa:30:cd:6b:9d:f5:bd:1d:e0:df:23:70:50:ed:21: f0:37:36:b0:d8:8f:39:ad:7b:c2:ab:68:cb:20:11: 4b:82:11:3f:45:b8:73:d2:2f:ff:6e:45:a8:04:fd:
da:b8:e2:cd
coefficient:
23:10:53:83:cc:aa:43:2d:c3:30:85:b1:5f:19:a8: b9:a4:0c:f9:f5:6e:29:c8:03:04:4b:60:57:2c:41: 10:ed:81:38:ba:af:27:33:dc:f9:35:84:25:73:05: fc:8c:77:cc:f0:aa:9c:0a:99:1e:45:a0:e5:ee:24:
4b:fe:99:58
Les différents éléments de la clé sont affichés en hexadécimal (hormis l’exposant public). On peut distinguer le modulus, l’exposant public (qui par défaut est toujours 655371), l’exposant privé, les nombres premiers facteurs du modulus, plus trois autres nombres qui servent à optimiser l’algorithme de déchiffrement.
On vérifie assez facilement avec 2 lignes de java que les 2 nombres premiers p et q font bien 1024 bits et que le modulus n = p x q
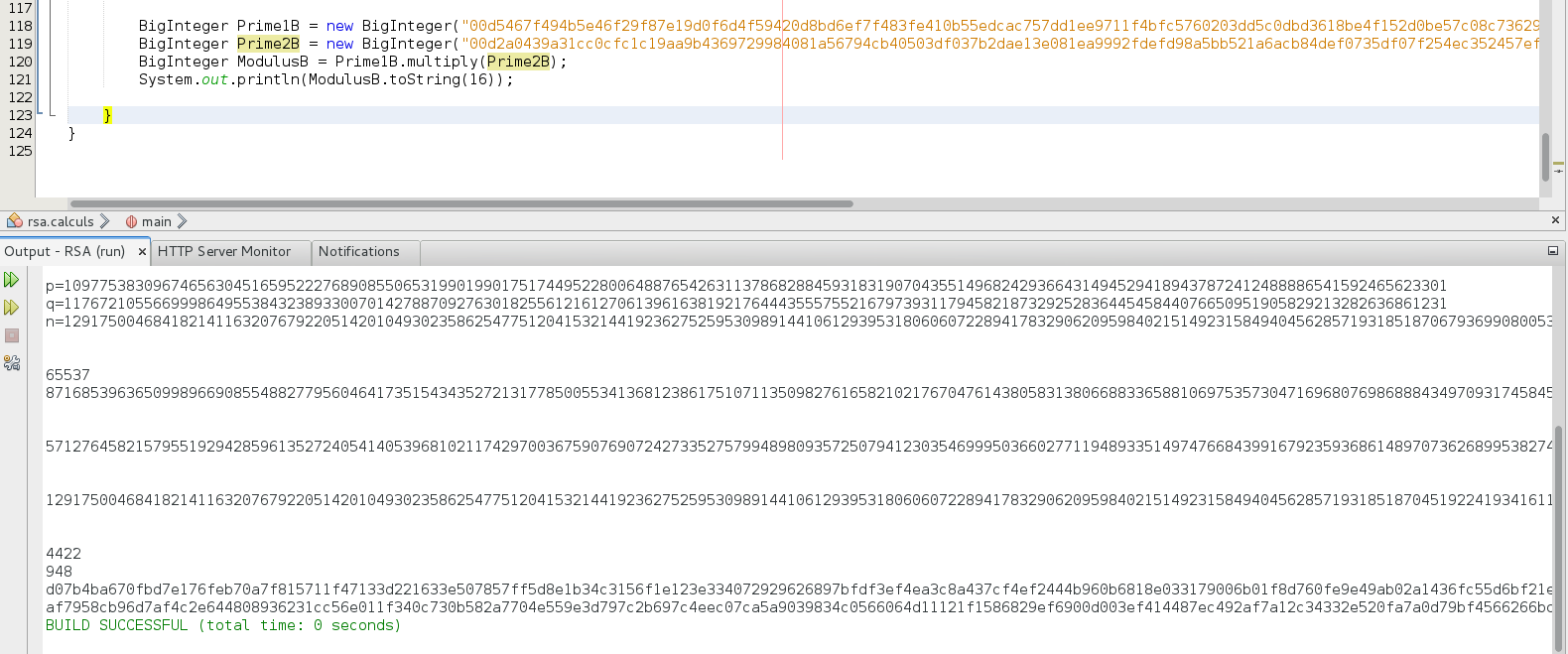
Playing with big numbers
Il n’est pas prudent de laisser une paire de clés en clair (surtout la partie privée). Avec la commande rsa, il est possible de chiffrer une paire de clés2. Pour cela trois options sont possibles qui précisent l’algorithme de chiffrement symétrique à utiliser : -des, -des3 et -idea.
$ openssl rsa -in maCle.pem -des3 -out maCle.pem writing RSA key Enter PEM pass phrase: Verifying - Enter PEM pass phrase:
Une phrase de passe est demandée deux fois pour générer une clé symétrique protégeant l’accès à la clé.
La partie publique d’une paire de clés RSA est publique, et à ce titre peut être communiquée à n’importe qui. Le fichier maCle.pem contient la partie privée de la clé, et ne peut donc pas être communiqué tel quel (même s’il est chiffré). Avec l’option -pubout on peut exporter la partie publique d’une clé.
$ openssl rsa -in maCle.pem -pubout -out maClePublique.pem
-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCveVjLltevTC5kSAiTYjHMVuAR
80DHMLWCp3BOVZ49eXwraXxO7AfKWpA5g0wFZgZNERIfFYaCnvaQDQA+9BRIfsSS
r3oSw0My5SD6eg15v0VmJmvPd8LgBypJHbr6f5MXWqntvzp0Qvg6ddeNpUIrqkkh
4uDfHFDWqyrkQUCvKwIDAQAB
-----END PUBLIC KEY-----
Mais pourquoi ma clé commence toujours par MIGf… ?
# openssl rsa -inform PEM -pubin -in maClePublique.pem -text -noout
Public-Key: (1024 bit)
Modulus:
00:af:79:58:cb:96:d7:af:4c:2e:64:48:08:93:62:
31:cc:56:e0:11:f3:40:c7:30:b5:82:a7:70:4e:55:
9e:3d:79:7c:2b:69:7c:4e:ec:07:ca:5a:90:39:83:
4c:05:66:06:4d:11:12:1f:15:86:82:9e:f6:90:0d:
00:3e:f4:14:48:7e:c4:92:af:7a:12:c3:43:32:e5:
20:fa:7a:0d:79:bf:45:66:26:6b:cf:77:c2:e0:07:
2a:49:1d:ba:fa:7f:93:17:5a:a9:ed:bf:3a:74:42:
f8:3a:75:d7:8d:a5:42:2b:aa:49:21:e2:e0:df:1c:
50:d6:ab:2a:e4:41:40:af:2b
Exponent: 65537 (0x10001)
On peut chiffrer des données avec une clé RSA. Pour cela on utilise la commande rsautl
$ openssl rsautl -encrypt -in <fichier_entree> -inkey <cle> \ -out <fichier_sortie
où
fichier_entree est le fichier des données à chiffrer. Attention, le fichier des données à chiffrer ne doit pas avoir une taille excessive (ne doit pas dépasser 116 octets pour une clé de 1024 bits).cle est le fichier contenant la clé RSA. Si ce fichier ne contient que la parte publique de la clé, il faut rajouter l’option -pubin.fichier_sortie est le fichier de données chiffré.Pour déchiffrer on remplace l’option -encrypt par -decrypt. Le fichier contenant la clé doit évidemment contenir la partie privée.
La commande dgst permet de le faire.
$ openssl dgst <hachage> -out <empreinte> <fichier_entree>
où hachage est une fonction de hachage. Avec openssl, plusieurs fonctions de hachage sont proposées dont
Dans la vraie vie signer un document revient à chiffrer son empreinte (et non pas à signer son empreinte comme on peut le lire dans le doc original, puisque la signature est une double opération cryptographique hash&encrypt). Pour cela, on utilise l’option -sign de la commande rsautl
$ openssl rsautl -sign -in <empreinte> \ -inkey <cle> \ -out <signature>
et pour vérifier la signature
$ openssl rsautl -verify -in <signature> -pubin \ -inkey <cle> -out <empreinte
Il reste ensuite à vérifier que l’empreinte ainsi produite est la même que celle que l’on peut calculer. L’option -pubin indique que la clé utilisée pour la vérification est la partie publique de la clé utilisée pour la signature.
Pour ceux qui ne veulent pas jouer avec Java : Command Line Utilities openSSL
Si vous voulez faire des tests en ligne (! confidentialité sur clefs privées), il existe de nombreux outils :
– https://8gwifi.org/ – PEM Parseur
– https://www.devglan.com/online-tools/rsa-encryption-decryption
– https://www.sslshopper.com/ssl-certificate-tools.html
Si vous voulez jeter un oeil sur une conf un peu trop provoc’ à mon goût : « Fuck RSA @SummerCon2019 »
Posted in Boulot0 commentaire
Posted on 27 mars 2020.
Sécuriser les données au repos c’est important, mais sécuriser les flux l’est tout autant.
Donc, après une petite synthèse sur Data-at-Rest Encryption avec Transparent Data Encryption, voyons comment mettre un peu de confidentialité dans le transport.
Un peu de cuisine pour commencer … En ces temps de confinement, cet article servira de support à un TP que nous jouerons avec les LP DLIS de l’IUT de Vannes semaine prochaine.
On va ouvrir un accès sur une base MariaDB exposée sur Internet … ouais, on des fous 🙂
Bon, on va quand même avant toute chose activer les logs sur le fameux SGBD histoire de voir qui attaque sans passer par un proxy. Attention malgré tout car dans les fameux fichiers de logs on retrouve aussi en particulier, les requêtes de création de comptes avec si on n’y prends pas garde le mot de passe en clair (et accessoirement toutes les commandes pourries) :
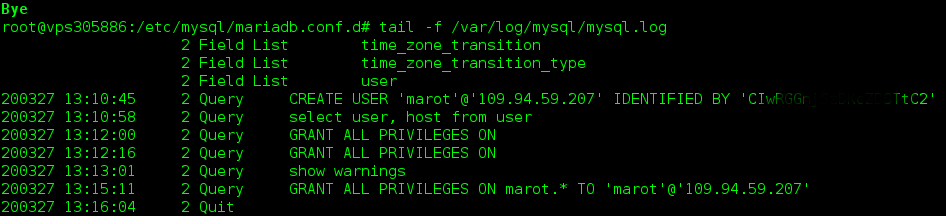
logs mariaDB
root@vpsxxxxxx:/etc/mysql/mariadb.conf.d# ls /var/log/mysql/mysql.log -lart
-rw-rw—- 1 mysql adm 182 Mar 27 11:56 /var/log/mysql/mysql.log
Pour faire les choses un petit peu sérieusement, on n’ouvrira qu’une base sur internet avec un seul compte dédié créé pour l’occasion, histoire d’avoir un peu de cloisonnement.
Forcément et heureusement, dans un premier temps ça ne passe pas. Il faut modifier la configuration par défaut qui n’autorise que les connexions depuis le poste local.
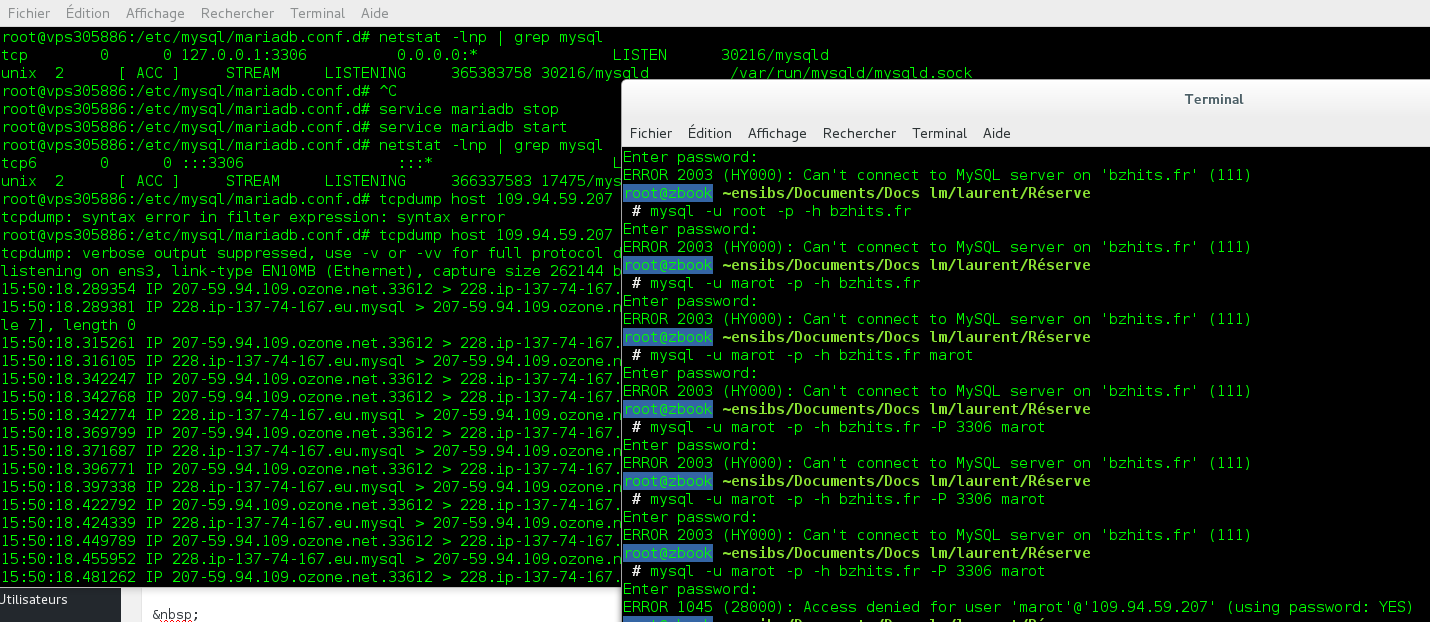
can’t connect to mariaDB
Et puis, après quelques efforts, la connexion peut enfin être établie…
mysql from everywher for everyone
Faudrait pas croire que votre mot de passe circule en clair (contrairement au trafic suivant l’authentification) .
Il se dit que le mot de passe suivrait le mécanisme de chiffrement détaillé ici :
Malheureusement, à cet instant (20200329151524) je n’arrive pas à retrouver dans mon pcap les 20 octets de nonce (on nous ment ?)
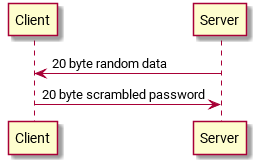
Scramble data
Bref, quoi, qu’il en soit et au delà de la vérification de l’implémentation de ce mécanisme, revenons au chiffrement du flux …
Créons un dossier tls dans le répertoire /etc/mysql/ (parce que ssl c’est tellement vingtième siècle):
$ cd /etc/mysql
$ sudo mkdir tls
$ cd tls
Note: La valeur du Common Name (CN) utilisée pour les certificats serveur MariaDB et le client doivent être différents du Common Name utilisé pour le certificat racine de l’autorité de certification. Pour éviter tour problème, j’ai utilisé les valeurs suivantes :
Common Name de la CA : MariaDB admin
Common Name du serveur : MariaDB server
Common Name du client : MariaDB client
Dans la vraie vie, la CA serait hébergée sur une autre machine.
Génération de la paire de clefs RSA
$ sudo openssl genrsa 2048 > BZHITSCA-key.pem
Génération du certificat de la clef publique ( tip : pour être très précis, on parle donc de certificat DE clef publique)
$ sudo openssl req -new -x509 -nodes -days 365000 -key BZHITSCA-key.pem -out BZHITSCA-cert.pem
On lui donne une validité de 1 000 ans, ce qui nous donnera le temps de jouer.
Par abus de langage on associe souvent la commande précédente à une simple génération de clef privée. Mais en fait le fichier .pem produit permet aussi d’exporter la clef publique.
$ sudo openssl rsa -in BZHITSCA-key.pem -pubout -out BZHITSCA-pubkey.pem
Génération de la clef et de la Certificate Signing Request
$ sudo openssl req -newkey rsa:2048 -days 365 -nodes -keyout SERVER-key.pem -out SERVER-req.pem
Le deuxième objet créé est la requête de demande de signature de certificat (Certificate Signing Request = CSR). Donc, généralement on peut dire qu’un certificat c’est un fichier contenant des « informations » relatives à une entité et la clef publique de cette même entité ayant subi une signature numérique par l’autorité de certification (qui certifie donc que la clef publique représente bien l’entité en question). Capito ?
Export de la clef RSA
$ sudo openssl rsa -in SERVER-key.pem -out SERVER-key.pem
Signature du certificat du serveur
$ sudo openssl x509 -req -in SERVER-req.pem -days 365000 -CA BZHITSCA-cert.pem -CAkey BZHITSCA-key.pem -set_serial 01 -out SERVER-cert.pem
Génération de la clef et de la Certificate Signing Request
$ sudo openssl req -newkey rsa:2048 -days 365 -nodes -keyout SERVER-key.pem -out SERVER-req.pem
Le deuxième objet créé est la requête de demande de signature de certificat (Certificate Signing Request = CSR). Donc, généralement on peut dire qu’un certificat c’est un fichier contenant des « informations » relatives à une entité et la clef publique de cette même entité ayant subi une signature numérique par l’autorité de certification (qui certifie donc que la clef publique représente bien l’entité en question). Capito ?
Export de la clef RSA
$ sudo openssl rsa -in SERVER-key.pem -out SERVER-key.pem
Signature du certificat du serveur
$ sudo openssl x509 -req -in SERVER-req.pem -days 365000 -CA BZHITSCA-cert.pem -CAkey BZHITSCA-key.pem -set_serial 01 -out SERVER-cert.pem
Configuration du client
mkdir /etc/mysql/client-ssl && cd /etc/mysql/client-ssl
# Copy the following files: CLIENT-cert.pem, CLIENT-key.pem and BZHITSCA-cert.pem
scp root@REMOTE_SERVER_IP:~/cert/{client-cert.pem,client-key.pem,ca-cert.pem} ./
chmod -R 700 /etc/mysql/client-ssl
Editer my.cnf pour configurer les chemins vers les certificats:
nano /etc/mysql/my.cnfet ajouter:
[client]
ssl-ca = /etc/mysql/client-ssl/ca-cert.pem
ssl-cert = /etc/mysql/client-ssl/client-cert.pem
ssl-key = /etc/mysql/client-ssl/client-key.pem
Editer le fichier /etc/mysql/mariadb.conf.d/50-server.cnf ou bien /etc/mysql/mariadb.cnf comme suit:
$ sudo vi /etc/mysql/mariadb.conf.d/50-server.cnf
Ajouter dans le bloc [mysqld]:
### MySQL Server ### ## Securing the Database with ssl option and certificates ## ## There is no control over the protocol level used. ## ## mariadb will use TLSv1.0 or better. ## ssl ssl-ca=/etc/mysql/ssl/ca-cert.pem ssl-cert=/etc/mysql/ssl/server-cert.pem ssl-key=/etc/mysql/ssl/server-key.pem |
Savegarder le fichier etredémarrer mariadb :
$ sudo /etc/init.d/mysql restart
CREATE USER 'secure_user'@'%' IDENTIFIED BY 'my_password';
GRANT ALL PRIVILEGES ON votre_base.* TO securee_user@'%' REQUIRE SSL;
FLUSH PRIVILEGES;
Vous pouvez alors en principe vous connecter avec TLS:
mysql -h REMOTE_SERVER_IP -u remote_user -p"my_password"
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 5
Server version: 10.1.26-MariaDB-0+deb9u1 Debian 9.1
Copyright (c) 2000, 2017, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> Bye
Pour mémoire (pas mal de liens qui m’ont permis de comprendre) :
https://stackoverflow.com/questions/38167587/how-to-use-wireshark-to-capture-mysql-query-sql-clearly
How to get the network packets between MySQL client and server?
tcpdump -nnei any port 3306 -w tmp.pcap
https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_connection_phase_authentication_methods_native_password_authentication.html
http://databaseblog.myname.nl/2017/03/network-attacks-on-mysql-part-1.html
https://www.cyberciti.biz/faq/how-to-setup-mariadb-ssl-and-secure-connections-from-clients/
https://www.gab.lc/articles/mysql_with_ssl/
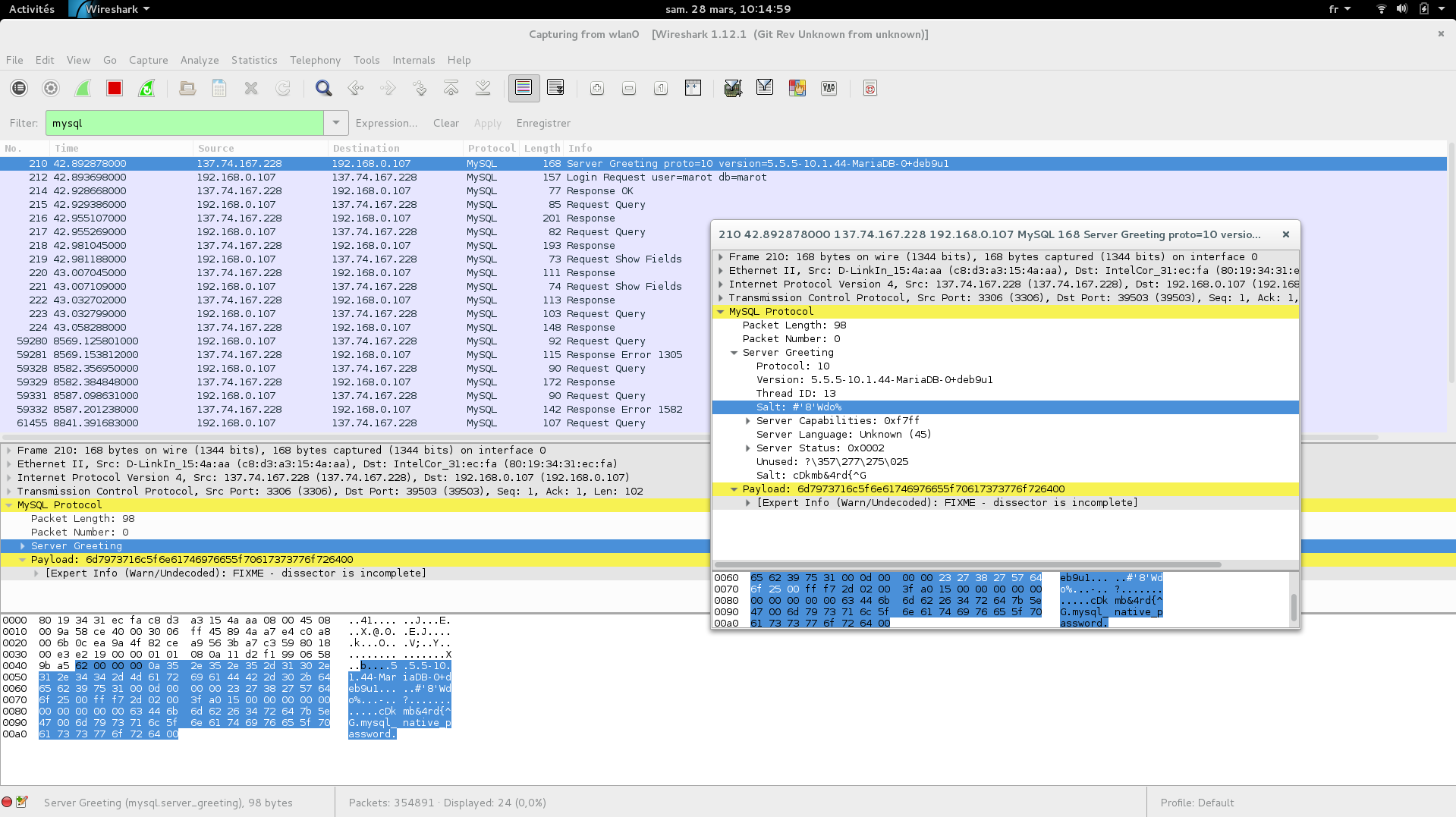
capture wireshark
Posted in Boulot0 commentaire
Posted on 27 mars 2020.
Pour occuper cette période un peu particulière de confinement COVID-19 et alimenter quelques menus TPs, je me lance dans la grande aventure de la tentative de compréhension d’InnoDB.
Si j’avais eu un peu de courage, je me serais remis à Ruby et j’aurais étudié les excellents travaux de Jeremy Cole https://blog.jcole.us/innodb/ mais vu que des chinois sympathiques semblent avoir porté son travail en java , let’s go !!
Jusqu’à la semaine dernière, utilisateur-amateur de MariaDB, je ne m’étais même jamais posé de questions sur les types de backend de mon SGBD. Je faisais juste le malin en allant lire vos tables à partir des fichiers MYD avec un pauvre éditeur hexadécimal.
J’ai donc téléchargé le dernier build du client innodb-java-reader et …
Bon, pour l’instant, on ne va pas se cacher, ça ne se passe pas très bien 🙂
alibaba /
innodb-java-reader
[2020-03-28] Puis après quelques échanges par mail avec Xu, nous avons fini par découvrir un bug lié à ma config (bon c’est sûr quand tu bosse sous windows pasr ce que ta Debian est bridée sur Java 7 …) .
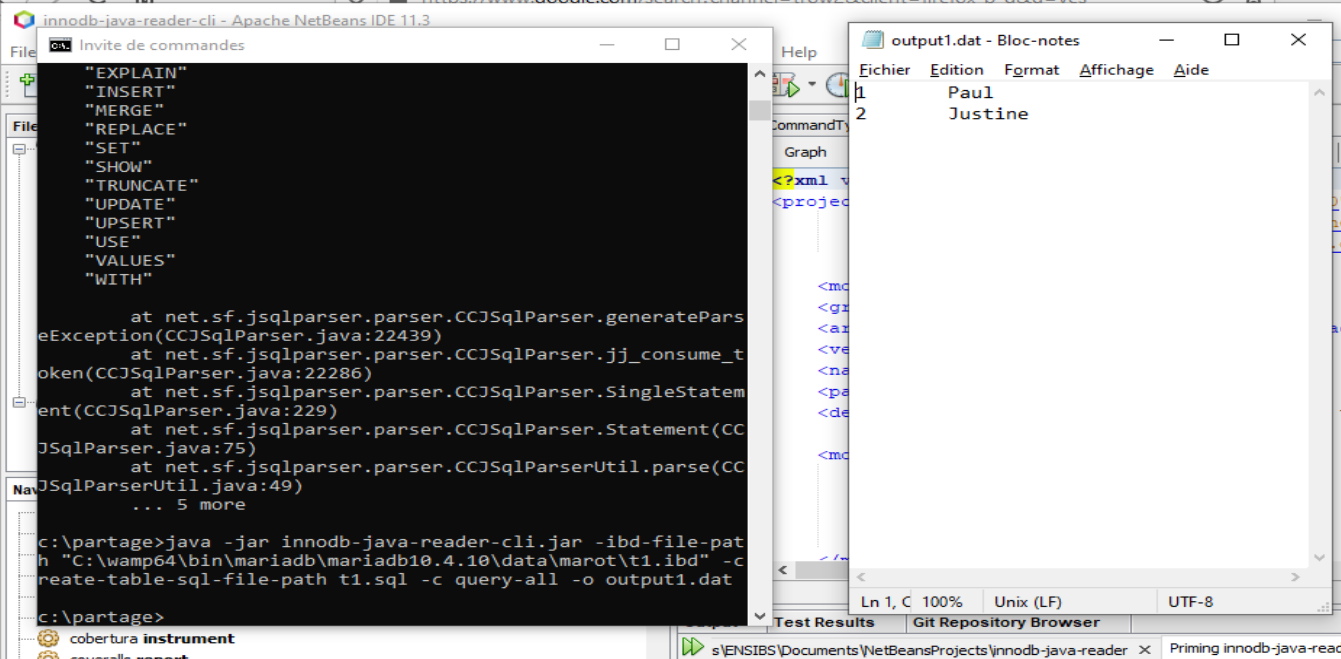
Read your data …
Je rappelle que l’objectif reste de pouvoir aller lire les fichiers InnoDB sans passer par le moteur MariaDB afin de démontrer la pertinence du chiffrement.
Posted in Boulot0 commentaire
Posted on 24 mars 2020.
Source : https://mariadb.com/kb/en/file-key-management-encryption-plugin/
Encryption of tables and tablespaces was added in MariaDB 10.1.3.
Having tables encrypted makes it almost impossible for someone to access or steal a hard disk and get access to the original data. MariaDB got Data-at-Rest Encryption with MariaDB 10.1. This functionality is also known as « Transparent Data Encryption (TDE) ».
This assumes that encryption keys are stored on another system.
Using encryption has an overhead of roughly 3-5%.
MariaDB encryption is fully supported for the XtraDB and InnoDB storage engines. Encryption is also supported for the Aria storage engine, but only for tables created with ROW_FORMAT=PAGE (the default), and for the binary log (replication log).
MariaDB allows the user to configure flexibly what to encrypt. In XtraDB or InnoDB, one can choose to encrypt:
Additionally, one can choose to encrypt XtraDB/InnoDB log files (recommended).
MariaDB’s data-at-rest encryption requires the use of a key management and encryption plugin. These plugins are responsible both for the management of encryption keys and for the actual encryption and decryption of data.
MariaDB supports the use of multiple encryption keys. Each encryption key uses a 32-bit integer as a key identifier. If the specific plugin supports key rotation, then encryption keys can also be rotated, which creates a new version of the encryption key.
How MariaDB manages encryption keys depends on which encryption key management solution you choose. Currently, MariaDB has three options:
The File Key Management plugin that ships with MariaDB is a basic key management and encryption plugin that reads keys from a plain-text file. It can also serve as example and as a starting point when developing a key management plugin.
For more information, see File Key Management Plugin.
The AWS Key Management plugin is a key management and encryption plugin that uses the Amazon Web Services (AWS) Key Management Service (KMS). The AWS Key Management plugin depends on the AWS SDK for C++, which uses the Apache License, Version 2.0. This license is not compatible with MariaDB Server’s GPL 2.0 license, so we are not able to distribute packages that contain the AWS Key Management plugin. Therefore, the only way to currently obtain the plugin is to install it from source.
For more information, see AWS Key Management Plugin.
The Eperi Key Management plugin is a key management and encryption plugin that uses the eperi Gateway for Databases. The eperi Gateway for Databases stores encryption keys on the key server outside of the database server itself, which provides an extra level of security. The eperi Gateway for Databases also supports performing all data encryption operations on the key server as well, but this is optional.
For more information, see Eperi Key Management Plugin.
The File Key Management plugin that ships with MariaDB is a key management and encryption plugin that reads encryption keys from a plain-text file.
The File Key Management plugin is the easiest key management and encryption plugin to set up for users who want to use data-at-rest encryption. Some of the plugin’s primary features are:
It can also serve as an example and as a starting point when developing a key management and encryption plugin with the encryption plugin API.
The File Key Management plugin is included in MariaDB packages as the file_key_management.so or file_key_management.dll shared library. The shared library is in the main server package, so no additional package installations are necessary.
Although the plugin’s shared library is distributed with MariaDB by default, the plugin is not actually installed by MariaDB by default. The plugin can be installed by providing the --plugin-load or the --plugin-load-add options. This can be specified as a command-line argument to mysqld or it can be specified in a relevant server option group in an option file. For example:
[mariadb] ... plugin_load_add = file_key_management
![]() The default MariaDB option file is called my.cnf on Unix-like operating systems and my.ini on Windows. Depending on how you’ve installed MariaDB, the default option file may be in a number of places, or it may not exist at all.
The default MariaDB option file is called my.cnf on Unix-like operating systems and my.ini on Windows. Depending on how you’ve installed MariaDB, the default option file may be in a number of places, or it may not exist at all.
In order to encrypt your tables with encryption keys using the File Key Management plugin, you first need to create the file that contains the encryption keys. The file needs to contain two pieces of information for each encryption key. First, each encryption key needs to be identified with a 32-bit integer as the key identifier. Second, the encryption key itself needs to be provided in hex-encoded form. These two pieces of information need to be separated by a semicolon.
$ sudo openssl rand -hex 32 >> /etc/mysql/encryption/keyfile $ sudo openssl rand -hex 32 >> /etc/mysql/encryption/keyfile $ sudo openssl rand -hex 32 >> /etc/mysql/encryption/keyfile
The key file still needs to have a key identifier for each encryption key added to the beginning of each line. Key identifiers do not need to be contiguous. Open the new key file in your preferred text editor and add the key identifiers. For example, the key file would look something like the following after this step:
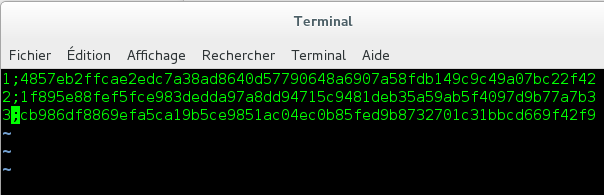 If the key file is unencrypted, then the File Key Management plugin only requires the
If the key file is unencrypted, then the File Key Management plugin only requires the file_key_management_filename system variable to be configured.
[mariadb] ... loose_file_key_management_filename = /etc/mysql/encryption/keyfile
Note that the loose option prefix is specified. This option prefix is used in case the plugin hasn’t been installed yet.
The File Key Management plugin currently supports two encryption algorithms for encrypting data: AES_CBC and AES_CTR. Both of these algorithms use Advanced Encryption Standard (AES) in different modes. AES uses 128-bit blocks, and supports 128-bit, 192-bit, and 256-bit keys. The modes are:
AES_CBC mode uses AES in the Cipher Block Chaining (CBC) mode.AES_CTR mode uses AES in two slightly different modes in different contexts. When encrypting tablespace pages (such as pages in InnoDB, XtraDB, and Aria tables), it uses AES in the Counter (CTR) mode. When encrypting temporary files (where the cipher text is allowed to be larger than the plain text), it uses AES in the authenticated Galois/Counter Mode (GCM).The recommended algorithm is AES_CTR, but this algorithm is only available when MariaDB is built with recent versions of OpenSSL. If the server is built with wolfSSL or yaSSL, then this algorithm is not available. See TLS and Cryptography Libraries Used by MariaDB for more information about which libraries are used on which platforms.
ENCRYPTED table option to YES, and the innodb_default_encryption_key_id system variable or the ENCRYPTION_KEY_ID table option refers to a non-existent key identifier. In this case, SHOW WARNINGS would return the following:SHOW WARNINGS; +---------+------+---------------------------------------------------------------------+ | Level | Code | Message | +---------+------+---------------------------------------------------------------------+ | Warning | 140 | InnoDB: ENCRYPTION_KEY_ID 500 not available | | Error | 1005 | Can't create table `db1`.`tab3` (errno: 140 "Wrong create options") | | Warning | 1030 | Got error 140 "Wrong create options" from storage engine InnoDB | +---------+------+---------------------------------------------------------------------+ 3 rows in set (0.00 sec)
see also https://severalnines.com/blog/exploring-different-ways-encrypt-your-mariadb-data
Posted in Boulot0 commentaire
Posted on 20 février 2020.
Bon il a fallu être patient cette année. La livraison a habituellement lieu à l’automne.
Ca y est, il est sorti … merci à Rapid7 pour l’info !
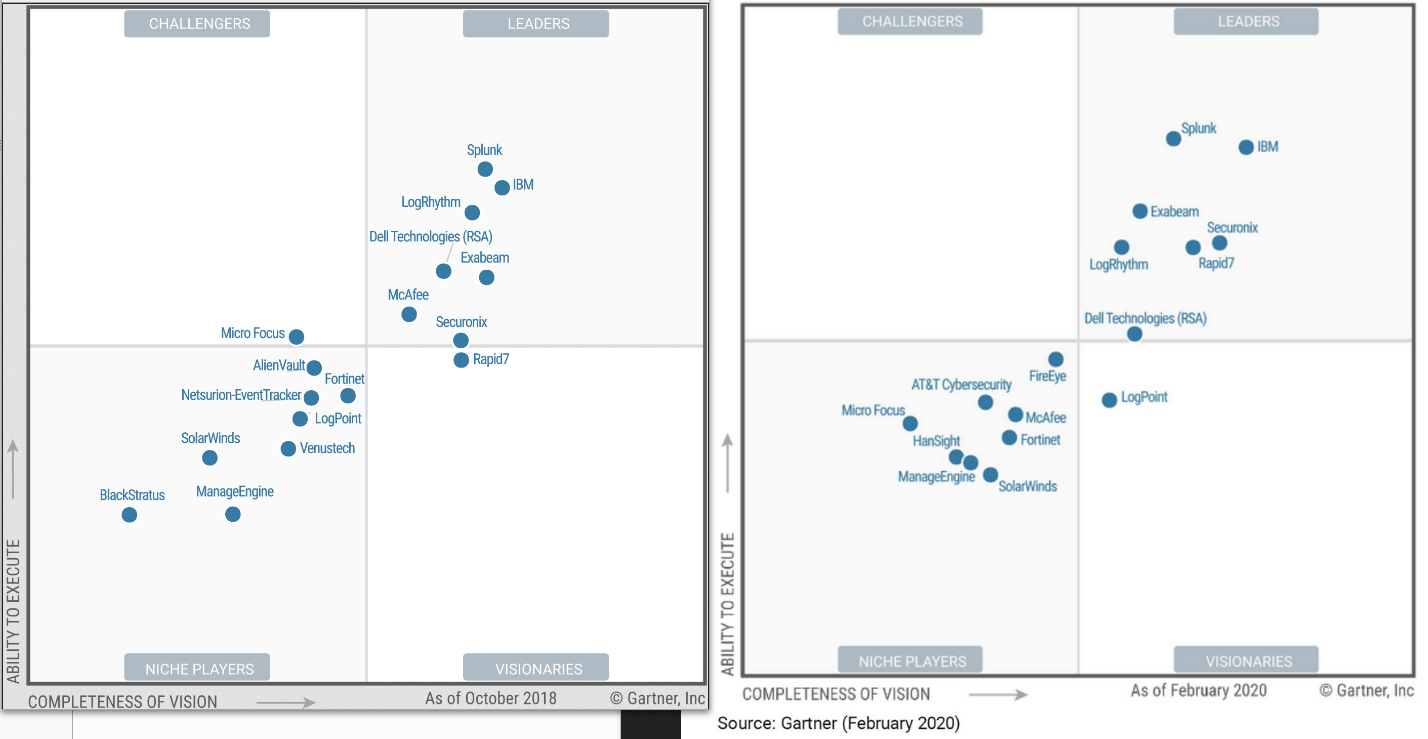
Qu’en dire ?
Ca ne bouge pas trop chez les tenors. Faudra lire le rapport complet et renommer RSA bradé à moins de 3 G$ par DELL.
Me suis toujours pas habitué au fait que AlienVault is Now AT&T Cybersecurity (juillet 2018).
Gartner n’oublie pas de nous rappeler que :
The complexity and cost of buying and running SIEM products, as well as the emergence of other security analytics technologies, have driven interest in alternative approaches to collecting and analyzing event data to identify and respond to advanced attacks. The combination of Elasticsearch, Logstash and Kibana (aka the ELK Stack or Elastic Stack) is a leading example. There has also been an emergence of alternatives to broad-based SIEM solutions that are focused primarily on the log collection and security analytics elements. Vendors competing in this space include Elastic.io, Cybraics, Empow, Elysium, Jask (acquired by Sumo Logic), MistNet, PatternEx, Qomplx, Rank Software and Seceon.
Posted in Boulot0 commentaire
Posted on 13 février 2020.
Posted in BoulotSaisissez votre mot de passe pour accéder aux commentaires.

© 2025 blog2Lau. Animé par Wordpress et mes petits doigts.
Thème par ![]()